本文共 36743 字,大约阅读时间需要 122 分钟。
连接步骤:
双击SecureCRT 打开软件;
选择快速连接; 协议:SSH2,主机名:IP地址,点击连接;(Cisco设备使用telnet登陆);视图模式介绍
1.普通视图router>
2.特权视图router# / 在普通模式下输入enable
3.全局视图router(config)#/ 在特权模式下输入configt
4.接口视图router(config-if)#/在全局模式下输入int 接口名称例如int s0 或 int e0
5.路由协议视图router ( config-route ) #/ 在全局模式下输入router 动态路由协议名称
switch> 用户模式 工作模式: 命令大致划分: v 用户模式下大多都是对设备IOS系统进行操作配置的一些命令。 v 特权模式下大多都是Show查看类命令。 v 全局模式下大多都是配置类命令。 v 接口模式下大多都是对于接口的配置命令。 CSICO基础常用命令
命令大致划分: v 用户模式下大多都是对设备IOS系统进行操作配置的一些命令。 v 特权模式下大多都是Show查看类命令。 v 全局模式下大多都是配置类命令。 v 接口模式下大多都是对于接口的配置命令。 CSICO基础常用命令 

1基本配置:
1. router>enable / 进入特权模式2. router#conft / 进入全局配置模式3. router(config)#hostname xxx /设置设备名称就好像给我们的计算机起个名字4. router(config)#enable password xxx /设置特权口令5. router(config)#no ip domain lookup /不允许路由器缺省使用DNS解析命令 6. router(config)#Service password-encryptio /对所有在路由器上输入的口令进行暗文加密 7. router(config)#line vty 0 4 /进入设置telnet服务模式 router(config-line)#password xxx /设置 telnet 的密码 router(config-line)#login /使能可以登陆8. router(config)#line con 0 /进入控制口的服务模式router(config-line)#password xxx /要设置 console 的密码 router(config-line)#login /使能可以登陆
2接口配置
1. router(config)# int s0/ 进入接口配置模式serial 0 端口配置 (如果是模块化的路由器前面加上槽 位编号,例如serial0/0 代表这个路由器的0 槽位上的第一个接口)2.router(config-if)#ip add xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx / 添加 ip 地址和掩码3.router(config-if)#enca hdlc /ppp捆绑链路协议hdlc 或者 ppp 思科缺省串口封装的链路层协议 是 HDLC 所以在 show run 配置的时候接口上的配置没有,如果要封装为别的链路层协议例如PPP/FR/X25就是看到接口下的enca ppp 或者 enca fr 4.router(config)#int loopback /建立环回口(逻辑接口 )模拟不同的本机网段router(config-if)#ip add xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx/ 添加ip 地址和掩码给环回口在物理接口 上配置了ip 地址后用no shut 启用这个物理接口反之可以用shutdown 管理性的关闭接口
3路由配置
1.静态路由router(config)#ip route xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx 下一跳或自己的接口2.缺省路由router(config)#ip route 0.0.0.0 0.0.0.0 s0 添加缺省路由3.动态路由rip 协议router(config)#router rip /启动 rip 协议router(config-router)#network xxx.xxx.xxx.xxx /宣告自己的网段router(config-router)#version 2 /转 换为 rip2 版本router(config-router)#noauto-summary /关闭自动汇总功能,ripV2才有作用router(config-router)#passive-in 接 口 名 / 启 动 本 路 由 器 的 那 个 接 口 为 被 动 接 口router(config-router)#neixxx.xxx.xxx.xxx /广播转单播报文,指定邻居的接 ip4.动态路由eigrp 协议router(config)#router eigrp xxx /启动 eigrp 协议router(config-router)#network xxx.xxx.xxx.xxx /宣告自己的网段router(config-router)#variance xxx /调整倍数因子,使用不等价的负载均衡eigrp 协议router(config-router)#noauto-summary /关闭自动汇总功能ospf 协议5.动态路由ospf协议router(config)router ospf xxx /启动协议router(config-router)network xxx.xxx.xxx.xxx xxx.xxx.xxx.xxx(反掩码)area xxx / 宣告自己的接口 或网段在ospf 的区域中可以把不同接口宣告在不同区域中
4保存当前修改/运行的配置:
1.router#write/将 RAM 中的当前配置存储到NVRAM 中,下次路由器启动就是执行保存的配置2.router#Copy running-config startup-config /命令与write 效果一样
5一般常用命令
1.exit命令router(config-if)#exitrouter(config)# router(config-router)#exitrouter(config)#router(config-line)#exitrouter(config)# router(config)#exitrouter#exit 命令 / 从接口、协议、line 等视图模式下退回到全局配置模式,或从全局配置模式退回到特权模式2.end命令router(config-if)#end router(config-router)#endrouter(config-line)#endrouter#end 命令 / 从任何视图直接回到特权模式3.logoutrouter#Logout / 退出当前路由器登陆模式相对与windows 的注销4.reload命令router#reload / 重新启动路由器 (热启动)冷启动就是关闭路由器再打开电源开关5.show 命令特权模式下:router#show ip route /查看当前的路由表router#cleariproute*/清楚当前的路由表 router#show ip protocol /查看当前路由器运行的动态路由协议情况router#show ip int brief /查看 当前的路由器的接口ip地址启用情况router#show running-config /查看当前运行配置 router#show startup-config /查看启动配置router#debug ip pack / 打开 ip 报文的调试 router#terminal monitor / 输出到终端上显示调试信息router#show ip eigrp neighbors /查看 eigrp 协议的邻居表router#show ip eigrp topology /查看 eigrp 协议 的拓朴表router#show ip eigrp interface /查 看当然路由器运行eigrp协议的 接口情况router#show ip ospf neighbor /查看当前路由器的ospf 协议的邻居表router#show ip ospf interface /查看当然路由器运行ospf协议的接口情况router#clear ip ospf process / 清楚当然路由器ospf 协议的进程router#Show interfaces / 显示设置在路由器和访问服务器上所有接口的统计信息. 显示路由器 上配置的所有接口的状态router#Show interfaces serial / 显示关于一个串口的信息router#Show ip interface /列出一个接口的IP 信息和状态的小结,列出接口的状态和全局参数
巡检命令
配置与软件 show running-config show version CPU与内存 show process cpu show process memory 风扇、电源 show environment alarm #查看设备环境告警# show environment temperatures #查看各插槽热点温度# show environment cooling al #查看风扇数量、状态、转速 show power #查看电源数量、各板卡消耗功率 模块 SN号 show module #查看引擎/线路卡/子卡的状态# show inventory #查看机箱中各模块名称、SN号# show hw-module subslot all oir #查看子模块是否工作正常# 日志信息 show logging 接口控制器状态 show controllers pos #查看POS接口低层信息,包括光衰减# 接口状态 show ip interface [brief] show interfaces VLAN信息 show vlan brief show ip interfaces brief | i Vlan 冗余性 show redundancy #查看引擎的主备统计信息、使用的冗余模式等# show redundancy switchover history #查看主备切换历史记录# 文件系统 show file systems #查看文件系统结构,带*的为默认FS# show disk0: #查看特定文件系统中的内容# show bootvar #查看引导变量# dir、pwd、cd等Unix命令 系统崩溃(crash)信息 show context #查看crash历史信息# dir /all bootflash: #查看是否有名为crashinfo的崩溃信息文件# show file information bootflash:crashinfo #查看崩溃信息文件内容# Debug信息 show debug 时钟信息 show clock detail 路由统计 show ip route summary
CISCO思科交换机命令

 CISCO思科路由命令:
CISCO思科路由命令:  注:下一跳地址为路由对端接口地址。 CISCO思科三层交换命令:
注:下一跳地址为路由对端接口地址。 CISCO思科三层交换命令: 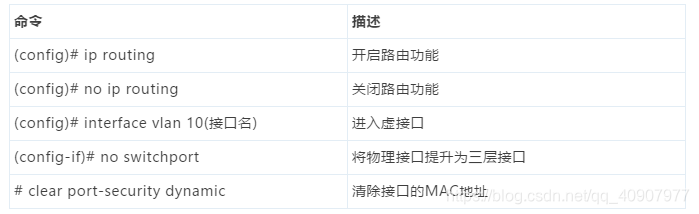 思科热备技术相关命令:
思科热备技术相关命令: 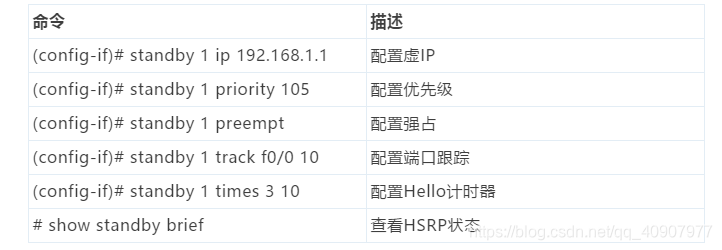 CISCO思科OSPF相关命令:
CISCO思科OSPF相关命令: 
 注:当接口Priority优先级为0时,表示不参与DR与BDR的选举。 思科ACL相关命令:
注:当接口Priority优先级为0时,表示不参与DR与BDR的选举。 思科ACL相关命令:  注:标准ACL只能用于入口,而扩展ACL可以应用于出入口。 Permit:允许,deny:拒绝,eq:等于,standad:标准,extended:扩展 案例:将ACL应用于远程登录。
注:标准ACL只能用于入口,而扩展ACL可以应用于出入口。 Permit:允许,deny:拒绝,eq:等于,standad:标准,extended:扩展 案例:将ACL应用于远程登录。 CISCO的PVST+生成树命令:
 注:速接口一般应用于PC接入口,可以关闭STP的收敛,达到迅速通信。 主根优先级默认为8192,副根优先级默认为16384.
注:速接口一般应用于PC接入口,可以关闭STP的收敛,达到迅速通信。 主根优先级默认为8192,副根优先级默认为16384. MSTP生成树多个VLAN可以共用一颗生成树。
MSTP生成树引入了域的概念,一个域中可以有多个实例,而一个实例可以理解为一个树。
Instance 0是一个特殊的树,只要启动了MST,它就默认启动,它是所有VLAN默认映射到这个实例中。
BPDU保护:当交换设备启动了BPDU保护功能后,如果边缘端口收到其他生成树的BPDU,边缘端口将自动Shutdown。
根保护:由于网络中恶意攻击,根网桥收到优先级更高的BPDU,根端口不在转发报文,当优先级恢复则恢复正常的状态。
CISCO思科链路聚合命令:
 注:捆绑接口后形成的通道被称为以太通道Channel。
注:捆绑接口后形成的通道被称为以太通道Channel。 重置密码
CISCO思科路由器密码恢复:
v 重启路由器,同时按下Ctrl+Break键中断IOS的加载,进入ROM系统。 v 修改配置寄存器的默认值0X2102改为0X2142,表示启动时忽略NV的配置。confreg 0x2142
reset
v 手动加载NV配置到RAM中。
# copy startup-config running-config
v 选择重置密码方式。
2 保留配置型密码重置:(config)# password 123(config)# config-register 0x2102 # wr
2 不保留配置型密码重置:
(config)# erase nvram(config)# config-register 0x2102 # wr
CISCO思科交换机密码恢复:
v 拔掉交换机电源插头。 v 按住mode键,重新插上电源,进入交换机ROM系统。 v 初始化Flash。Switch: flash_init
v 将config.text文件改为config.old。
Switch: rename flash:config.text flash:config.old
v 重启交换机。
Switch:reboot
v 选择重置密码方式。
2 保留配置型密码重置:# rename flash:config.old flash:config.text # copy flash:config.text system:running-config# password 123# wr
2 不保留配置型密码重置:
#delete config.old#copy flash:config.text system:running-config #wr
CISCO思科交换机路由配置VTY虚拟终端:
v 创建并进入一个虚接口:(config)# interface vlan 10v 配置虚接口地址:(config-if)# ip add 192.168.1.1 255.255.255.0v 打开虚接口:(config-if)# no shutdownv 配置默认网关:(config)#default-gateway 192.168.1.254v 创建并进入VTY配置:(config)# line vty 0 4v 设置VTY密码:(config-line)#password 123v 打开普通密码认证:(config-line)#loginv 设置Enable密码:(config-line)#enable password 123
1:进入特权模式enable
switch> enableswitch#
2:进入全局配置模式configure terminal
switch> enableswitch#configure terminalswitch(conf)#
3:交换机命名hostname name 以cisco001 为例
switch> enableswitch#c onfigure terminalswitch(conf)#hostname cisco001cisco001(conf)#
4:配置使能口令(未加密)enable password cisco 以cisco 为例
switch> enableswitch#configure terminalcisco001(conf)# enable password cisco
5:配置使能密码(加密)enable secret ciscolab 以cicsolab 为例
switch> enableswitch#configure terminalswitch(conf)# enable secret ciscolab
6:设置虚拟局域网vlan 1 interface vlan 1
switch> enableswitch#configure terminalswitch(conf)# interface vlan 1switch(conf)# ip address 192.168.1.1 255.255.255.0 配置交换机端口ip 和子网掩码switch (conf-if)#no shut 激活端口switch (conf-if)#exitswitch (conf)#ip default-gateway 192.168.254 设置网关地址
7:进入交换机某一端口interface fastehernet 0/17 以17 端口为例
switch> enableswitch#configure terminalswitch(conf)# interface fastehernet 0/17switch(conf-if)#
8:查看命令show
switch> enableswitch# show version 察看系统中的所有版本信息show interface vlan 1 查看交换机有关ip 协议的配置信息show running-configure 查看交换机当前起作用的配置信息show interface fastethernet 0/1 察看交换机1 接口具体配置和统计信息show mac-address-table 查看mac 地址表
9:交换机恢复出厂默认恢复命令
switch> enableswitch# erase startup-configureswitch# reload
10:交换机的密码恢复
拔下交换机电源线。
用手按着交换机的MODE 键,插上电源线
在switch:后执行flash_ini 命令:switch: flash_ini
查看flash 中的文件: switch: dir flash:
把“config.text”文件改名为“config.old”: switch: rename flash: config.text flash: config.old
执行boot: switch: boot
交换机进入是否进入配置的对话,执行no :
进入特权模式察看flash 里的文件: show flash :
把“config.old”文件改名为“config.text”: switch: rename flash: config.old flash: config.text
把“ config.text ” 拷入系统的“ running-configure ”: copy flash: config.text system :
running-configure
重新设置密码并保存。
11.交换机telnet 远程登录设置:
switch>enswitch#configure terminalswich(conf)#enable password cisco 以cisco 为特权模式密码swich(conf)#interface vlan 1 以vlan 1端口作为远程登录的接口,其他端口亦可swich(conf-if)#ip address 192.168.1.1 255.255.255.0swich(conf-if)#no shutswich(conf-if)#exitswich(conf)line vty 0 4 设置0-4 个用户可以telnet 远程登陆swich(conf-line)#loginswich(conf-line)#password 123456
12.交换机ssh远程登录设置:
a.设定一个非默认的hostname
Switch(config)#hostname cisco
b.配置域名:
cisco(config)#ip domain-name test
c.指定加密长度:
cisco(config)#crypto key generate rsa
How many bits in the modulus [512]: 1024
% Generating 1024 bit RSA keys, keys will be non-exportable…[OK]
d.将vty线路下的登录方式改为 ssh
cisco(config)#line vty 0 4cisco(config-line)#transport in ssh
13.配置vtp同步
说明:VTP(VLAN Trunking Protocol):是VLAN中继协议,它是思科私有协议。作用是同步各个交换机之间的VLAN信息。
14、调试命令Switch#show run 显示所有配置命令Switch#show ip inter brief 显示所有接口状态Switch#show vlan brief 显示所有VLAN的信息Switch#show version 显示版本信息
接口配置命令
Switch(config)#interface f0/8 进入接口视图Switch(config-if)#no shut 此命令开启接口Switch(config-if)#description to server01 端口描述Switch(config-if)#ip add 192.168.1.100 255.255.255.0 设置接口IP
VLAN配置命令
建立和删除VLANSwitch# vlan databaseSwitch(vlan)# vlan 20 name test20Switch(vlan)# no vlan 20Switch(vlan)# exit将端口分配给一个VLANSwitch(config)# interface f0/1Switch(config-if)# switchport mode accessSwitch(config-if)# switchport access vlan 20设置VLAN TRUNKSwitch(config)# interface f0/24Switch(config-if)# switchport mode trunkSwitch(config-if)#switchport trunk allow vlan {ID|All}Switch(config-if)# switchport trunk encapsulation dot1q 端口镜像配置命令
配置镜像源端口Switch(config)#monitor session 1 source interface gigabitEthernet 0/2 - 5 rx
上面命令最后一个参数:
both 监听双向数据,默认为both rx 接收 tx 发送配置镜像目的端口
Switch(config)#monitor session 1 destination interface gigabitEthernet 0/6
删除镜像端口
Switch(config)#no monitor session 1
冗余配置
思科HSRP:Switch# interface Vlan20ip address 172.29.197.33 255.255.255.248standby 20 ip 172.29.197.53standby 20 priority 105 优先级standby 20 preempt 抢占standby 20 track GigabitEthernet0/25 decrement 10 跟踪端口如果DOWN了优先级减10
设置安全远程访问
思科设置vty安全访问:R1(config)# access-list 1 permit 192.168.2.5R1(config)# line vty 0 4R1(config)# access-class 1 in
网管配置
思科:Switch(config)#snmp-server community sunion ro 配置本交换机的只读字串为sunionSwitch(config)#snmp-server community sunion rw 配置本交换机的读写字串为sunionSwitch(config)#snmp-server enable traps 允许交换机将所有类型SNMP Trap发送出去Switch(config)#snmp-server host 192.168.190.1 traps sunion 指定交换机SNMP Trap的接收者为192.168.190.1,发送Trap时采用sunion作为字串
Cisco交换机IOS配置介绍
一、模式
• 用户模式(>):
• 特权模式(#): • 全局配置模式(config#): • 接口配置模式(config-if#): • 线路模式(#config-line):二、基本IOS命令结构
•每个IOS 命令都具有特定的格式或语法,并在相应的提示符下执行。
•常规命令语法为命令后接相应的关键字和参数。 •某些命令包含一个关键字和参数子集,此子集可提供额外功能。三、相关配置
1、 进入用户模式,命令提示符是>号(正常登陆设备CLI(command-line interface,命令行界面)后的第一个配置模式,主要用于查看统计信息,可用的命令比较少,查看部分简单配置,不可修改,配置)
Switch>Switch>?Exec commands:connect Open a terminal connectiondisable Turn off privileged commandsdisconnect Disconnect an existing network connectionenable Turn on privileged commandsexit Exit from the EXEClogout Exit from the EXECping Send echo messagesresume Resume an active network connectionshow Show running system informationtelnet Open a telnet connectionterminal Set terminal line parameterstraceroute Trace route to destination
2、 输入enable进入特权模式,命令提示符是#号(从用户模式进入,可用命令比较多,查看所有配置,部分修改(保存,恢复出厂等))
Switch>enableSwitch#Switch#?Exec commands:clear Reset functionsclock Manage the system clockconfigure Enter configuration modeconnect Open a terminal connectioncopy Copy from one file to anotherdebug Debugging functions (see also 'undebug')delete Delete a filedir List files on a filesystemdisable Turn off privileged commandsdisconnect Disconnect an existing network connectionenable Turn on privileged commandserase Erase a filesystemexit Exit from the EXEClogout Exit from the EXECmore Display the contents of a fileno Disable debugging informationsping Send echo messagesreload Halt and perform a cold restartresume Resume an active network connectionsetup Run the SETUP command facilityshow Show running system information--More--
3、 输入disable从特权模式退到用户模式
Switch#disableSwitch>
4、 输入configure terminal进入全局配置模式(需要从特权模式进入,在全局模式下执行命令将影响整个设备,大配置操作都在这个模式下或从这个模式进入其他模式)
Switch#configure terminalSwitch(config)#
5、输入exit从全局配置模式退到特权模式
Switch(config)#exitSwitch#
6、在全局配置模式下可以设置特权密码(进入特权模式的密码,用于限制人员访问特权执行模式),输入enable password
Switch(config)#enable password 1234 #密码为1234Switch>enablePassword: #再从用户模式进入特权模式提示输入密码
7、进入某个接口配置模式
Switch(config)#interface vlan 100Switch(config-if)#Switch(config)#interface gigabitEthernet 0/1Switch(config-if)#
8、现在开始配置vlan 100 的管理ip 和子网掩码
Switch(config-if)#ip address 192.168.100.100 255.255.255.0
9、配置一条线路(实际线路或虚拟线路,每个连接这个设备的用户都要占用一个线路例Console、AUX 或VTY等连接方式,这里VTY(Virtual Type Terminal) 是虚拟终端的意思)
Switch(config)#line vty 0 4line vty 0 4表示设置0到4号5个线路为远程登录,设置为0 3,0 2,0 1完全是可以的,0 4表示最多可以同时5个线路连接,默认0线路被Console占用)Switch(config-line)#
10、在全局配置模式下可以设置Console密码(用于限制人员通过控制台(Console)连接访问设备)
Switch(config)#line console 0 #配置console线路Switch(config-line)#password 1234 #密码为1234Switch(config-line)#login #登录启用密码检查
11、在全局配置模式下可以设置VTY线路登录密码(用于限制人员通过VTY接访问设备)
Switch(config)#line vty 0 10 #通过VTY线路同时连接的最大用户是10Switch(config-line)#password 12345 #VTY线路登录密码12345Switch(config-line)#login #登录启用密码检查
Cisco ASA 使用ASDM 配置管理口 方法
CISCO ASA防火墙ASDM安装和配置
准备一条串口线一边接台式机或笔记本一边接防火墙的CONSOLE 接口,通过CRT或者超级终端连接ASA 在用ASDM图形管理界面之前须在串口下输入一些命令开启ASDM。 在串口下输入以下命令:CiscoASA>CiscoASA> enPassword:CiscoASA# conf t 进入全局模式CiscoASA(config)#webvpn 进入WEBVPN模式CiscoASA(config)# username cisco password cisco 新建一个webvpn用户和密码CiscoASA(config)# interface m0/0 进入mgmt接口CiscoASA(config-if)# ip address 192.168.100.1 255.255.255.0 配置添加MGMT接口IP地址CiscoASA(config-if)# nameif guanli 给管理口设个名字为管理CiscoASA(config-if)# no shutdown 激活接口CiscoASA(config)#quit 退出接口CiscoASA(config)# http server enable 开启HTTP服务CiscoASA(config)# http 192.168.100.0 255.255.255.0 inside 在接口设置可管理的IP地址段CiscoASA(config)# show run 查看一下配置CiscoASA(config)# wr 保存
经过以上配置就可以用ASDM配置防火墙了。
首先用交叉线(现在不区分直通和交叉,网口都有自适应)把电脑和防火墙的管理口相连,把电脑设成和管理口段的IP地址,本例中设为192.168.1.0 段的IP打开浏览器在地址栏中输入管理口的IP地址: https://192.168.100.1/admin 弹出一下安全证书对话框,单击 “是” 输入用户名和密码,然后点击“确定”。 出现以下对话框,点击“Download ASDM Launcher and Start ASDM”开始安装ASDM管理器,安装完以后从网上下载一个JAVA虚拟机软件(使用1.4以上 Java 版本),进入www.java.com下载安装,安装完后点击下面的“Run ASDM as a Java Applet ”。 出现以下对话框, 点击“是”。 出现以下对话框,输入用户名和密码(就是在串口的WEBVPN模式下新建的用户和密码),然后点击“是”。 出现以下对话框,点击“是”。 这样就可以通过ASDM来配置防火墙了。 以后就可以直接使用ASDM来管理防火墙了。cisco查看机框 板卡 电源 SN 风扇环境运行状态和一些常用命令 巡检命令
查看设备运行环境及状态
show environment 查看设备环境show environment temperature --查设备温度show environment fans --查看设备风扇show cpu usage 查看CPU利用率show memory 查看内存show perfmon 查看性能show logging --查日志show versionshow processes cpu-usage --查CPU详细进程show processes memory --查内存详细进程show route --查路由表show failover 查备援助线路show nameif 查看接口show int ip brief 查看接口状态show vlan --查看vlan信息
1、 清除NAT缓存:clear ip nat translation *
2、清除交换机上的所有配置:erase nvram/wrie erase------>reload(重启)
3、设置路由器telnet管理:en----->conf t------>line vty 0 4------>login------>password cisco4、设置交换机telnet管理:en----->conf t------>interface vlan 1------>no shut------>ip address 192.168.0.253------->enable password cisco
如果想管理其他网段的交换机需设置网关:ien----->conf t------>p default-gateway
192.168.0.254 ------->telnet 192.168.1.253
5、查看硬件信息:show idb all show version
75系列查看机框序列号:show diag 查看板卡序列号:show rsp chassis-info 7513查看板卡序列号:show diagbus 6509:show module (后可加参数)
show idprom (后可参数,可查如风扇、电源等序列号等)
6、使日志同步(可取消输入命令时系统自动生成的日志):logging synchronous
7、超时设置:A、登陆超时(输入用户名和密码时):timeout login response 20(20秒)
B、登陆后无操作超时:exec-timeout 0 0(为永不超时)
8、配置SSH:
Router(config)#ip http serverRouter(config)#ip http secure-serverRouter(config)#ip http authentication localRouter(config)#username cisco privilege 15 password 0 ciscoRouter(config)#line console 0Router(config-line)#login localRouter(config-line)#exitRouter(config)#line vty 0 4Router(config-line)#privilege level 15Router(config-line)#login localRouter(config-line)#transport input telnetRouter(config-line)#transport input telnet sshRouter(config-line)#^ZRouter#conf tRouter(config)#int f0/0Router(config-if)#ip address 1.1.1.1 255.255.255.0Router(config-if)#no shutRouter(config-if)#do ping 1.1.1.2!!!!!
打开WEB,输入https://1.1.1.1 进行连接测试
9、配置无线:
Router(config)#int dotl1radio 0Router(config-if)# ip address 10.1.12.1 255.255.255.0Router(config-if)#no shutRouter(config-if)#ssid WIRELESSRouter(config-if-ssid)#guest-modeRouter(config-if-ssid)#authentication openRouter(config-if-ssid)#infrastructure-ssidRouter(config-if-ssid)#exitRouter(config-if)#line con 0Router(config-line)#password consoleRouter(config-line)#logging syncRouter(config-line)#exec-timeout 0 0Router(config-line)#exit.........
10、配置DHCP:
Router(config)#ip dhcp pool R3WLANRouter(dhcp-config)#network 10.11.2.0 255.255.255.0Router(dhcp-config)#default-router 10.1.12.1Router(dhcp-config)#exitRouter(config)#ip dhcp excluded-address 10.1.12.1
11、清除ASA5510的配置:write erase/重新加载:reload
12、思科IOS基本配置
R(config)#hostname wildlee——设置思科IOS系统名称R(config)#no ip domain lookup——关闭域名解析功能Wildlee(config)#line console 0—-指定控制线路Wildlee(config)#line vty 0 15—–指定虚拟终端访问线路Wildlee(config-line)#exec-timeout 5 0—–指定线路超时时间5分0秒Wildlee(config-line)#password wildlee—–指定console线路的访问密码为wildleeWildlee(config)#enable secret wildlee——设置特权访问密码为wildleeWildlee(config)#service password-encryption——加密明文密码Wildlee(config)#banner motd $this is text$——欢迎广告词
VLAN配置命令
1.创建vlan
Wildlee(config)#vlan {vlan id}——–给vlan设置IDWildlee(config-vlan)#name {vlan name}———给vlan取名 2.配置中继端口
wildlee(config-if)#switchport trunk encapsulation dot1q———-定义中继端口封装模式wildlee(config-if)#switchport mode trunk ————-配置端口为中继端口
3.划分端口
wildlee(config)#interface {interface}——-指定要加入vlan的接口wildlee(config)#interface range {interface},{interface}——-将多个不连续端口划分到vlanwildlee(config)#interface range {interface 0/1 – 20}———将多个连续的端口划分到vlanwildlee(config-if)#speed {10|100|1000}——指定接口速率wildlee(config-if)#duplex {auto|half|full}——-指定双工模式wildlee(config-if)#switchport mode access————将指定接口定义为访问端口wildlee(config-if)#switchport access vlan id———–将指定端口分配到特定vlanwildlee#show mac-address-table ——-查看接口MAC地址列表wildlee#show mac-address-table aging-time ———-查看交换机MAC地址学习老化时间wildlee(config)#mac-address-table aging-time time[s]———修改此时间值 4.给vlan配置IP
wildlee(config)#interface vlan {vlan id}———指定VLAN号wildlee(config-vlan)#ip address {ip address与 netmask}—–给vlan配置IP地址用于vlan间路由 5.查看配置
wildlee#show interface fastEthernet {interface}———查看指定接口wildlee#show interface fastEthernet {interface} switchport——-查看交换机端口状态及封装模式wildlee#show ip interface brief———查看接口摘要信息wildlee#show vlan-switchport——-查看vlan接口配置情况 VTP配置命令
Wildlee(config)#vtp domain {vtp name}———配置vtp域名Wildlee(config)#vtp mode {server|client|transparent}——–配置配置vtp工作模式Wildlee(config)#vtp password {vtp password}——-给vtp设置密码Wildlee(config)#vtp pruning ——-启用vtp修剪Wildlee#show vtp status——查看vtp配置情况Wildlee#show vtp counters——-显示vtp消息发送与接收情况 典型VTP与VLAN配置过程
a.设置VTP DOMAIN(核心、分支交换机上都设置)
b.配置中继(核心、分支交换机上都设置)
c.创建VLAN(在server上设置)
d.将交换机端口划入VLAN
e.配置三层交换
STP生成树协议
wildlee(config)#spanning-tree vlan { vlan id}——-开启生成树协议wildlee(config)#spanning-tree vlan { vlan id} root primary——-设置为根交换机wildlee(config)#spanning-tree vlan { vlan id} priority { bridge priority}——-设置交换机ID优先级值wildlee(config-if)#spanning-tree vlan { vlan id} cost { cost}———设置交换机端口成本值wildlee(config-if)#spanning-tree vlan { vlan id} port-priority { priority}———设置端口优先级wildlee#show spanning-tree——-查看生成树信息 设定交换机MAC地址老化时间
switch(config)#mac-address-table aging-time <10-1000000>--------默认是300秒
设定交换机端口/MAC绑定
switch(config)#mac-address-table static 0100.5e00.0005 vlan 1 interface f0/1
13、ip unnumbered Loopback0 借用端口IP地址命令
“借用IP地址”实际就是:一个接口上没有配置IP地址,但是还想使用该接口。就向其它有IP地
址的接口借一个IP地址来。如果被借用接口有多个IP地址,只能借来主IP地址。如果被借用接口没有 IP地址,则借用接口的IP地址为0.0.0.0。该功能通过Ip unnumbered命令来实现。cisco 常用命令
1、show running 查看临时配置2、show start-up 查看启动配置3、copy run start 将临时配置保存4、write 将临时配置保存5、erase nvram: 删除nvram中的内容6、line console 0 进入console口password xxx 设置密码login 开启
7、enable password xx 设置特权模式密码8、enable secret xx 设置密文特权密码9、service password-encryption 将所有明文密码加密10、flash_init 初始化flash11、rename flash:config.text flash:config.old 重命令config.text的文件12、boot/reboot 启动和重启13、copy flash:config.text system:running-config 将config.text考入到当前临时配置中14、init vlan 1 进入VLAN115、line vty 0 4 进入虚拟类型终端password 设置密码login 开启
16、ip default-gateway 默认网关17、ip routing / no ip routing 开启路由功能(适用于三层交换)18、copy tftp flash 将tftp的内容拷入到flash中19、copy flash tftp 将flash的内容考入到tftp中20、ip ftp username 创建ftp用户名21、ip ftp password 创建ftp密码22、copy ftp flash 将ftp的内容考入到flash中23、show version 查看版本相关信息24、arp 192.168.1.1 000C.HI44.H14S #arpa 将192.168.1.1和mac地址绑定25、show ip arp 查看arp相关信息26、show mac-address-table 查看mac地址表27、vlan database 进入VLAN数据库vlan 10 name benet 创建一个vlan10,名称为benetexit 退出
28、int f0/0 进入到指定接口switchport mode access 将接口设置为链路模式switchport access vlan 10 将接口加入到vlan 10exit 退出
30、show vlan brief 查看vlan信息31、switchport trunk allow vlan remove vlan 10 指定接口连接不允许vlan 10通过,即不对vlan10封装32、show int f0/0 switchport 查看接口33、switch trunk native vlan 10 将接口设置为本地vlan34、int range f0/1 -4 进入1-4接口channel group 1 mode on 配置以太网通道,组号为1.35、show ethernet 1 summary 查看以太网通道136、int f0/0:1 进入子接口encapsulation dot1q vlan 10 为vlan10进行dot1q封装37、ip dhcp pool poolname 创建一个地址池38、network 192.168.1.0 255.255.255.0 网段作用域39、default-router 192.168.1.1 网关40、dns-server 202.106.196.115 dns地址41、lease 10 租约(天)42、ip dhcp excluded-address 192.168.1.100 排除地址43、vtp domain benet 创建vtp域44、vtp mode server 配置为服务器模式45、vtp passwork benet 配置vtp密码46、vty prunning 配置vtp修剪47、vtp version 配置vtp版本48、show vty password 查看vtp密码49、show vtp status 查看vtp状态50、int f0/0 进入接口no switchport 配置为非交换接口(路由接口)51、show ip route 查看路由表52、ip route network mask via 配置静态路由53、ip helper-address 192.168.100.100(dhcp-server) 为vlan启用dhcp中继54、show spanning-tree 查看生成树55、spanning-tree vlan 10 单个vlan的生成树56、spanning-tree vlan 10 priority 4096 设置vlan的优先级(根网桥)57、spanning-tree vlan 10 root primary/second 设置vlan为根网桥58、spanning-tree vlan 10 cost 10 设置端口成本59、spanning-tree vlan 10 port-priority 40 设置端口的优先级60、spanning-tree postfast 配置为速端口61、shoow spannint-tree vlan 10 detail 详细查看vlan10的生成树62、show standby 查看热备组63、int vlan 10 进入vlan1064、standby 10 ip 192.168.1.254 创建一个热备组,组号为10,虚拟ip为192.168.1.25465、standby 10 priority 200 优先级为20066、standby 10 preemt 配置占先权67、show standby brief 查看热备信息68、standby 10 track f0/1 100 跟踪端口f0/1,如果出现链路失效,则优先级降低10069、duplex half/full 配置双工模式为半双工或全双工70、speed 10/100 配置接口速率71、show int f0/1 查看端口配置72、no ip domain-lookup 不进行域名查询73、line con 0exec timeout 0 0logging synchronous
74、clear arp-cache 清除arp缓存75、default int f0/0 将端口恢复为默认76、access-list 1 permit/deny 192.168.1.0 0.0.0.255 标准ACL77、access-list 2 permit/deny host 192.168.1.100 标准ACL78、access-list 3 permit/deny any 标准ACL79、int f0/0ip access-group 1 in/out ACL应用到接口,通常是in80、access-list 100 permit ip 192.168.1.0 .0.0.0.255 192.168.2.0 0.0.0.255 扩展ACL81、show access-list 查看ACL82、access-list 101 permit tcp host 192.168.2.100 80 host 192.168.1.200 eq 80/www 扩展ACL加端口access-list 101 permit tcp 192.168.3.0 0.0.0.255 host 192.168.1.200 eq 21/ftp 允许访问FTPint f0/1ip access-group 101 in83、access-list 102 permit icmp 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 echo 允许ping84、ip access-list standard benet 标准命名ACLpermit 192.168.1.0 0.0.0.25585、ip access-list extended accp 扩展命名ACL,可以单独删除ACL中的某条规则permit tcp 192.168.1.0 0.0.0.255 host 192.1681.100 eq 8015 deny tcp host 192.168.1.200 host 192.168.1.100 eq 80 规则序号15,相当于插入no 10 删除ACL中的某条规则86、ip nat inside source static 192.168.1.100 200.0.0.1 创建静态映射,主要用于外访问内,保护内网int f0/0 进入接口ip nat inside 设置为insideint f0/1 进入接口ip nat outside 设置为outside87、 ip nat inside source static tcp 192.168.1.100 80 192.168.2.100 80 extend 静态88、 ip nat pool poolname 61.159.62.131 61.59.62.190 netmask 255.255.255.192 定义地址池access-list 1 permit 192.168.1.0 0.0.0.255 定义标准ACLip nat insdie source access 1 pool poolname 进行动态NAT转换89、 ip nat inside source access 1 int f0/0 overload 进行PAT转换90、 show ip nat translation 显示NAT信息91、 show ip nat statictisc 查看NAT统计信息92、 debug ip nat 实时查看NAT转换
防火墙部分
93、 hostname 配置主机名94、 password cisco 配置远程登录密码95、nameif inside 修改接口逻辑名称nameif outside 修改接口逻辑名称nameif dmz 修改接口逻辑名称security-level 50 修改接口安全级别96、show conn detail 查看状态链接表97、access-list out_to_in permit ip 192.168.1.0 255.255.255.0 192.168.2.0 255.255.255.0 定义ACLaccess-group out_to_in in interface outside 将ACL应用到outside接口的入站方向防火墙上的接口不能应用标准ACL,一般流量过滤都用扩展ACL来实现access-list nat permit 192.168.1.0 255.255.255.0 定义标准ACL,识别范围98、router outside 0 0 via 静态路由99、show route 查看路由表100、write memory 保存当前配置101、 clear configure all 清除所有配置clear configure 相当于 no101、 nat (inside) 1 192.168.1.0 255.255.255.0 定义需要转换的地址和id102、 globle (outside) 1 172.16.1.100-172.16.1.200 定义转换后的地址,id和inside对应globle (dmz) 1 192.168.1.100-192.168.1.200 定义从dmz区出去的地址转换103、 static (inisde,outside) 200.0.0.1 192.168.1.1 静态转换,通常与ACL结合使用access-list out_to_in permit ip any host 200.0.0.1 定义任何流量访问200.0.0.1access-group out_to_in in int outside 应用到外网接口104、 nat (inside) 1 0 0 0=0.0.0.0=any 转换所有流量105、 globle (outside) 1 interface PAT转换为接口地址106、 show xlate detail 查看NAT转换表107、 static (inside,outside) tcp 200.0.0.1 http 192.168.1.1 http 静态PAT,端口映射static (insdie,outside) tcp 200.0.0.1 21 192.168.1.1 21 访问200的21端口映射为192的21端口108、 nat-control 全部启用NAT109、 access-list nonat permit ip 192.168.1.0 255.255.255.0 host 200.0.0.1 通常用于内网访问DMZnat (inside) 0 access-list nonat 流量豁免110、 telnet 192.168.1.0 255.255.255.0 insdie 允许从inside接口telnet登录111、 domain-name benet.com 定义域名hostname asa 定义主机名crypto key generate rsa modulus 1024 生成秘钥对ssh 0 0 outsidessh 0 0 inside 允许ssh登录112、 ssh version 更改ssh版本113、 http server enable 开启https服务http 192.168.1.0 255.255.255.0 inside 允许登录asdm image disk0:/asdmfile 指定映像文件位置username benet password 123456 privilege 15 配置用户名密码和安全级别114、clock timezone peking 8 配置时区115、clock set 12:00:00 12 Oct 2013 配置时间116、logging enable 启用日志117、logging buffered information 日记information级别的日志,相当于本地记录日志118、show logging 查看日志记录信息119、clear loggging buffered 清除日志120、logging asdm informational 记录日志信息到asdm121、logging trap informational 记录日志信息到日志服务器logging timestamp 启用时间戳logging host 192.168.1.100 日志服务器的地址122、 firewall transparetns 防火墙透明模式,接口无需配置ip地址(默认路由模式)123、show firewall 查看防火墙当前模式124、ip address 192.168.1.1 255.255.255.0 配置管理地址125、show mac-address-table 查看mac地址表126、mac-address-table aging-time 10 动态mac过期时间路由器×××(L2L)127、crypto isakmp policy 1 创建isakmp管理连接策略集1encryption 3des 加密算法 3deshash sha 哈希算法shaauthencation pre-share 验证方式预共享密钥life 10000 管理连接生存周期group 2 DH算法组号access-list 100 ermit ip 192.168.1.0 0.0.0.255 192.168.2.0 0.0.0.255 定义保护流量ACLcrypto isakmp key 0 benet-key address ip 共享密码和对端地址crypto ipsec transform-set benet-set esp-3des esp-sha-hmac 定义数据传输集,协议为ipsecmode tunnel 定义传输模式exitcrypto ipset security-association lifetime seconds 1800 数据链接的SA周期crypto map benet-map 1 ipsec-isakmp 创建映射,将管理策略集和数据传输集应用到接口set peer ip 对端地址set transform-set benet-set 传输集match address 100 匹配的ACLint f0/0crypto map benet-map 将映射应用如端口防火墙×××(L2L)128、access-list nonat extend permit ip 192.168.1.0 255.255.255.0 192.168.2.0 255.255.255.0定义NAT豁免的流量nat-contral 启用NAT控制nat (inside) 1 0 0 NAT转换glocal (outside) 1 interface NAT转换接口nat (inside) 0 access-list nonat NAT豁免crypto isakmp enable outside 启用isamkp策略集crypto isamkp policy 1 同路由器crypto isamkp key benet-key address ip 共享秘钥tunnel-group 200.0.0.1 type ipset-l2ltunnel-group 200.0.0.1 ipset-attributespre-share-key benet-key 创建隧道组,等于共享秘钥的命令access-list *** extend permit ip 192.168.1.0 255.255.255.0 192.168.2.0 255.255.255.0 定义访问流量crytop ipsec transform benet-set esp-3des esp-md5-hmaccrypto map benet-map 1 match address 100crypto map benet-map 1 set peer 200.0.0.2crypto map benet-map 1 set transform-set benet-setcrypto map benet-map interface outside129、same-security-traffic permit intra-(inside\outside) 允许流量从一个接口进入并留出,通常为outside
路由器做 远程访问×××(IPSEC)
130、aaa newm-odelaaa authencation login benet-authen localaaa authorization netwokr benet-author localusername benet secres ciscocrypto isakmp policy 10encryption 3deshash shaauthencation pre-sharegroup 2exitip local pool benet-pool 192.168.1.200-192.168.1.210ip access-list extedned split-aclpermit ip ip 192.168.0.0 0.0.0.255 anyexitcrypto isakmp client configuratuon group test-groupkey benet-keypool benet-pooldns 192.168.0.10acl split-aclsplit-dns benet.comexitcrypto ipsec transform-set benet-set esp-3des esp-sha-hmacexitcrypto dynamic-map benet-dynap 1set transform-set benet-setexitcrypto map benet-stamap 1000 ipsec-isakmp dynamic benet-dymapcrypto map benet-stamap client authentication list benet-authencrypto map benet-stamap isakmp authorization list benet-authorcrypto map benet-stamap client configuration address respondint f0/1crypto mao benet-stamap
防火墙做远程访问×××( IPSEC)
131、username benet password ciscocrypto issakmp enable outsidecrypto isakmp policy 10encryption 3deshash shagroup 2authentication pre-shareexitip local pool benet-pool 192.168.1.200-192.168.1.210access-list split-acl permit ip 192.168.0.0 255.255.255.0 anygroup-policy test-group internlgroup-policy test-attributessplit-tunnel-policy tunnelspecfiedsplit-tunnel-network-list value split-aclexittunnel-group benet-group type ipsec-ratunnel-group benet-group general-attributesaddress-pool benet-pooldefault-group-policy test-groupexittunnel-group benet-group ipsec-attributespre-share-key benet-keyexitcrypto ip sec transform-set bente-set esp-3des esp-sha-maccrypto dynamic-map benet-dymap 1 set transfrom-set benet-setcrypto map benet-stamap 1000 ipsec-isakmp dynamic benet-dymapcrypto map benet-stamap int outside
无客户端SSL ×××
132、web***enable outsideexitusername benet passwork ciscogroup-policy ***_group internalgroup-policy ***_group attributes***-tunnel-protocal web***exittunnel-group ***_tunnel_group type web***tunnel-group ***_tunnel_group general-attributesdefault-group-policy ***_groupauthentication-server-group LOCALexittunnel-group ***_tunnel_group web***-attributesgroup-alias groups enableexitweb***tunnel-group-list enable
胖客户端SSL ×××
133、username benet passwork ciscoweb***enable outsidesvc image disk0:/sslclient-win-1.1.3.173.pkgsvc enabletunnel-group-list enableexitip local pool ssv***_pool 192.168.1.200-192.168.1.210group-policy ***_group_policy internalgroup-policy ***_group_policy attributes
-tunel-protocal web svc
web***svc ask enableexitexittunnel-group ***_group type web***tunnel-group ***_group general-attributesaddress-pool ssl***_pooldefault-group-policy ***_group_policyexittunnel-group ***_group web***-attributesgroup-alias groups enableexitaccess-list split_tunnel permit ip 192.168.0.0 255.255.255.0 anygroup-policy ***_group_policy attributessplit-tunnel-policy tunnelspecifiedsplit-tunnel-network-list value split_tunneldns value 192.168.0.10split-dns value benet.comexittunnel-group ***_group1 type web***tunnel-group ***_group1 general-attributesaddress-pool ssl***_pooldefault-group-policy ***_group_policyexittunnel-group ***_group1 web***-attributesgroup-alias caiwu enableexitusernamme benet attraibutesgroup-lock value ***_group
cisco交换机常用配置命令
思科交换机的基本配置
一、基本配
switch>enable //进入特权模式switch#config terminal //进入全局配置模式switch(config)#hostname //设置交换机的主机名switch(config)#enable secret xxx //设置进入特权MD5加密口令switch(config)#enable password xxa //设置进入特权明文加密口令switch(config)#line console 0 //进入控制台口switch(config-line)#line vty 0 4 //设置进入虚拟终端的连接数目 0~4 5个switch(config-line)#login //允许登录switch(config-line)#password xx //设置登录到普通用户口令xxswitch#exit //返回命令
二、交换机vlan的配置
switch#vlan database //进入VLAN设置switch(vlan)#vlan 2 //建VLAN 2switch(vlan)#no vlan 2 //删vlan 2Switch(config)# interface range fastethernet 0/1-5 //进入同种类型多端口配置
三、端口操作
switch(config)#int f0/1 //进入端口1switch(config-if)#switchport access vlan 2 // 将端口1当前端口加入vlan 2switch(config-if)#switchport mode trunk //将f0/1设置为中继干线switch(config-if)#switchport trunk allowed vlan 1,2 //设置允许通过中继的vlanswitch(config-if)#switchport trunk encap dot1q //设置vlan 中继执行的协议
LAN的端口聚合叫TRUNK,用来在不同的交换机之间进行连接,以保证在跨越多个交换机上建立的同一个VLAN的成员能够相互通讯。
本质上解决同一 vlan 下,不同主机直接互通 ,不需要把交换机的端口一个一个于另一个交换机上的端口对应链接 ,只需要连接一条,并把这条线所在的双方端口都设置成trunk口就可以了
其中 vlan 模式 有三种 trunk , hybrid ,access Access类型的端口 一般用于连接计算机的端口(非特定 端口); Trunk类型的端口可以允许多个VLAN通过,可以接收和发送多个VLAN的报文,一般用于交换机之间连接的端口; dynamic 将端口模式设定为 动态接入模式 ,可trunk可 access四、设置vtp
switch(config)#vtp domain //设置发vtp域名switch(config)#vtp password //设置发vtp密码switch(config)#vtp mode server //设置发vtp模式switch(config)#vtp mode client //设置发vtp模式
这里要说下,什么是VTP协议。
**VTP:**是VLAN中继协议,也被称为虚拟局域网干道协议。它是思科私有协议。作用是十几台交换机在企业网中,配置VLAN工作量大,可以使用VTP协议,把一台交换机配置成VTP Server, 其余交换机配置成VTP Client,这样他们可以自动学习到server 上的VLAN 信息。VTP的用途 通常情况下,我们需要在整个园区网或者企业网中的一组的交换机中保持VLAN数据库的同步,以保证所有交换机都能从数据帧中读取相关的VLAN信息进行正确的数据转发,然而对于大型网络来说,可能有成百上千台交换机,而一台交换机上都可能存在几十乃至数百个VLAN,如果仅凭网络工程师手工配置的话是一个非常大的工作量,并且也不利于日后维护——每一次添加修改或删除VLAN都需要在所有的交换机上部署。在这种情况下,我们引入了VTP。五、交换机设置IP地址:
switch(config)#interface vlan 1 //进入vlan 1switch(config-if)#ip address //设置IP地址switch(config)#ip default-gateway //设置默认网关switch#dir flash: //查看闪存
六、交换机显示命令
switch#write //保存配置信息switch#show vtp //查看vtp配置信息switch#show run //查看当前配置信息switch#show vlan //查看vlan配置信息switch#show interface //查看端口信息switch#show int f0/0 //查看指定端口信息
七、交换机配置保存
Switch#show running-config //查看交换机配置Switch#copy running-config startup-config //保存交换机配置
备注,关于保存的方式:
1、在接口配置模式下使用 do wr 或者是 do copy running-config startup-config 2、在全局配置模式下使用不带do的命令(以上两个)wr或者copy running-config startup-config思科交换机的二层交换机的配置
二层交换机的配置(配置二层交换机可远程管理)
配置如下: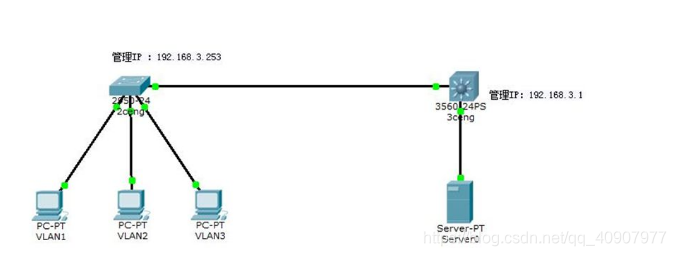
Switch>Switch>en //进入特权模式Switch#config //进入全局配置模式Switch(config)#hostname 2ceng //更改主机名为2ceng2ceng(config)#interface vlan 1 //进入VLAN 12ceng(config-if)#no shut //激活VLAN12ceng(config-if)#exit //退出到全局配置模式2ceng(config)#interface vlan 2 //创建VLAN 22ceng(config-if)#no shut //激活VLAN22ceng(config-if)#exit //退出到全局配置模式2ceng(config)#interface vlan 3 //创建VLAN 32ceng(config-if)#no shut //激活VLAN32ceng(config-if)# ip address 192.168.3.254255.255.255.0 //配置192.168.3.254为2ceng管理IP2ceng(config-if)#exit //退出到全局配置模式 2ceng(config)#interface range fa0/1-12 //进入到端口1-122ceng(config-if-range)#switchport mode access //将1-12口设置为交换口2ceng(config-if-range)#switch access vlan 1 //将1-12口划分到VLAN 12ceng(config-if-range)#exit //退出到全局配置模式 2ceng(config)#interface range fa0/13-23 //进入到端口13-232ceng(config-if-range)#switch access vlan 2 //将13-23口划分到VLAN22ceng(config-if-range)#exit //退出到全局配置模式 2ceng(config)#interface fastEthernet 0/24 //进入到24口2ceng(config-if)#switch mode trunk //将24口设置为干线2ceng(config-if)#exit //退出到全局配置模式 2ceng(config)#enable secret cisco //设置加密的特权密码cisco2ceng(config)#line vty 0 4 // VTY是路由器的远程登陆的虚拟端口,0 4表示可以同时打开5个会话,line vty 04是进入VTY端口,对VTY端口进行配置,比如说配置密码2ceng(config-line)#password telnet //设置远程登陆密码为telnet2ceng(config-line)#login2ceng(config-line)#exit2ceng(config)#ip default-gateway 192.168.3.12ceng(config)#exit2ceng#wr //保存配置Building configuration...[OK]
参考链接 :
cisco查看机框 板卡 电源 SN 风扇环境运行状态和一些常用命令 巡检命令 :https://www.cnblogs.com/qzqdy/p/9040323.html
Cisco ASA 使用ASDM 配置管理口 方法 https://www.cnblogs.com/qzqdy/p/9040872.html
Cisco交换机IOS配置介绍 :https://www.cnblogs.com/pipci/p/8116655.html
cisco 常用命令 : https://blog.51cto.com/1283684/2125304
思科交换机-常用命令及配置 :https://www.cnblogs.com/guoxh/p/7481866.html干货 | 思科和华为交换机命令对比,做项目必备!快收藏!!https://mp.weixin.qq.com/s/_gcDNUgbLorX9DKg-PhcLw
cisco交换机常用配置命令 https://mp.weixin.qq.com/s/DCESTa-i9BjNNUF_eB9JYA